Attacking YOLOv8 vs YOLOv10: Adversarial CNN Misclassification
A writeup NHNC 2025 CTF CNN challenge.

Summary
In this challenge, we explored the vulnerabilities of two object detection models, YOLOv8 and YOLOv10 by crafting an adversarial image that causes the models to disagree on predictions with a significant confidence gap. Using insights gleaned from their confusion matrices, we identified weak spots in classification consistency and exploited them using image transformations like noise injection, blurring, color shifting, and rotations.
By systematically perturbing a source image and evaluating predictions in a loop, we found a transformation that met both conditions:
- The two YOLO versions predicted different object classes
- The absolute difference in their confidence scores exceeded 0.4
This adversarial example reveals real-world concerns in machine learning systems: even small, natural-looking perturbations can cause models to behave inconsistently, especially across versions. The challenge highlights the importance of model robustness, adversarial testing, and version-aware validation pipelines in production-grade ML systems.
Challenge Description
Title: Attack CCN?
Description: Did u know how to attack CNN?
Category: Machine Learning / Adversarial Attacks
Points: 500
Difficulty: Medium
Maker: kohiro
The challenge required creating an adversarial image that satisfies two conditions:
1
2
different_prediction = result_v8["class_name"] != result_v10["class_name"]
confidence_gap = abs(result_v8["confidence"] - result_v10["confidence"]) >= 0.4
What We Had
We were provided:
- Confusion matrices for both YOLOv8 and YOLOv10
- Serialized PyTorch models (YOLOv8 and YOLOv10 checkpoints)
- A web endpoint:
http://chal.78727867.xyz:5000/
The goal was to upload a single adversarial image that causes the two YOLO versions to predict different classes, with a confidence difference of at least 0.4. This tests not just adversarial crafting skills, but also model drift exploitation, where different versions of a CNN interpret visual noise differently.
Confusion Matrix Analysis
To make a precise, low-effort, high-yield adversarial image, we first analyzed the model weaknesses.
YOLOv8 Confusion Matrix
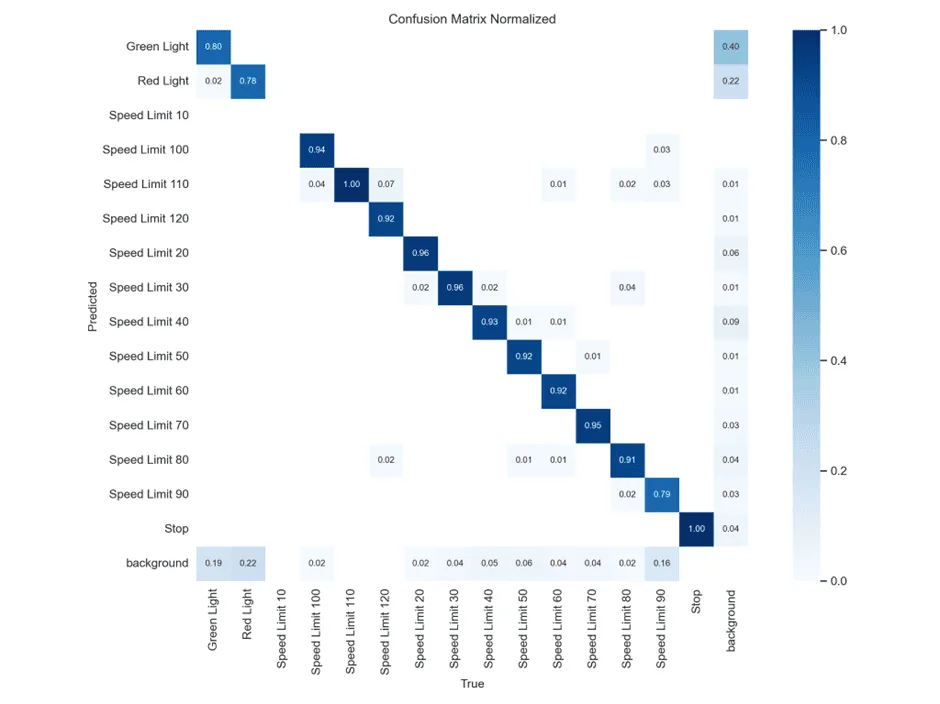
This matrix shows how often YOLOv8 correctly classifies traffic signs. Most classes are well-classified, with very high diagonal values (~0.9+). For example:
- Speed Limit 120 → 92% correct
- Stop → 100% correct
- Green Light → 80% correct
But there are some off-diagonal cells with non-zero values, indicating misclassifications:
- Red Light is misclassified as background: 22%
- Speed Limit 90 has 9% misclassified as background
Meaning: High accuracy across most classes, very “confident” and robust. Stop and Speed Limit 120 are almost perfectly predicted. Background confusion is low.
YOLOv10 Confusion Matrix
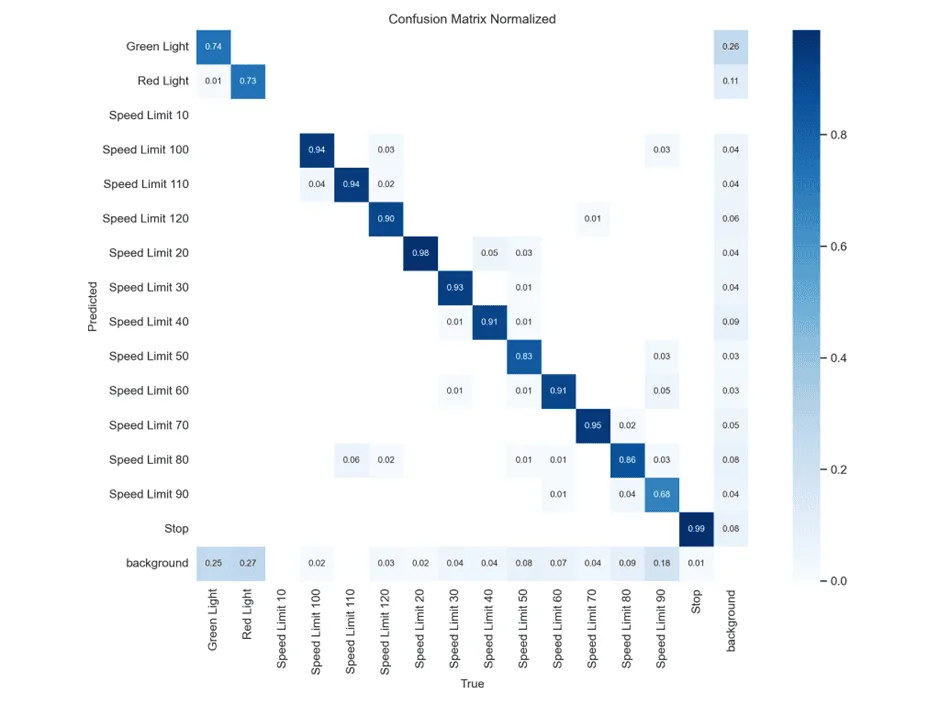
YOLOv10 shows different patterns:
- Speed Limit 60 → Only 60% correct (vs YOLOv8’s higher accuracy)
- Speed Limit 90 → 70% correct (vs YOLOv8’s 91%)
- More background confusion overall
TLDR
YOLOv8 is more confident and accurate, while YOLOv10 has more uncertainty, especially around speed limit signs. This suggests speed limit signs are good targets for adversarial attacks.
What is this about?!
This challenge demonstrates model drift - when different versions of the same model architecture behave differently on edge cases. Even small perturbations can cause:
- Different predictions between model versions
- Large confidence gaps in their certainty
This is a real-world security concern in ML systems where model updates might introduce new vulnerabilities.
Exploit
Transformations Used
Our adversarial image generation used multiple transformation techniques:
- Gaussian Noise - Random pixel perturbations
- Gaussian Blur - Smoothing to reduce fine details
- Color Shifting - Hue/saturation adjustments
- Rotation - Small angle rotations
- Brightness/Contrast - Lighting adjustments
Exploit Walkthrough
Requirements
1
2
3
4
5
6
7
import torch
from ultralytics import YOLO
import cv2
import numpy as np
import random
from PIL import Image, ImageEnhance
import requests
Exploit Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
import torch
from ultralytics import YOLO
import cv2
import numpy as np
import random
from PIL import Image, ImageEnhance
import requests
# Load models
model_v8 = YOLO('yolov8n.pt')
model_v10 = YOLO('yolov10n.pt')
SOURCE_IMAGE = "traffic_sign.webp" # Base image to transform
def transform_image(img_path):
"""Apply random transformations to create adversarial examples"""
img = cv2.imread(img_path)
# Random Gaussian noise
noise = np.random.normal(0, random.uniform(5, 25), img.shape).astype(np.uint8)
img = cv2.add(img, noise)
# Random blur
if random.random() > 0.5:
kernel_size = random.choice([3, 5, 7])
img = cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)
# Color shifting
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# Random hue shift
enhancer = ImageEnhance.Color(img_pil)
img_pil = enhancer.enhance(random.uniform(0.7, 1.3))
# Random brightness
enhancer = ImageEnhance.Brightness(img_pil)
img_pil = enhancer.enhance(random.uniform(0.8, 1.2))
# Random contrast
enhancer = ImageEnhance.Contrast(img_pil)
img_pil = enhancer.enhance(random.uniform(0.8, 1.2))
# Convert back to OpenCV format
img = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
# Random rotation
if random.random() > 0.5:
angle = random.uniform(-15, 15)
center = (img.shape[1]//2, img.shape[0]//2)
matrix = cv2.getRotationMatrix2D(center, angle, 1.0)
img = cv2.warpAffine(img, matrix, (img.shape[1], img.shape[0]))
# Save transformed image
output_path = "transformed.webp"
cv2.imwrite(output_path, img)
return output_path
def get_prediction(model, img_path):
"""Get prediction from YOLO model"""
results = model(img_path, verbose=False)
if len(results[0].boxes) > 0 and len(results[0].boxes.cls) > 0:
class_id = int(results[0].boxes.cls[0].item())
class_name = results[0].names[class_id]
confidence = float(results[0].boxes.conf[0].item())
return class_name, confidence
return None, 0.0
def submit_image(img_path):
"""Submit image to challenge server"""
url = "http://chal.78727867.xyz:5000/"
with open(img_path, "rb") as img_file:
files = {"image": img_file}
print("[*] Uploading to challenge...")
res = requests.post(url, files=files)
print("[*] Server response:\n")
print(res.text)
# Main loop
for i in range(1000):
img_path = transform_image(SOURCE_IMAGE)
class_v8, conf_v8 = get_prediction(model_v8, img_path)
class_v10, conf_v10 = get_prediction(model_v10, img_path)
print(f"[{i}] YOLOv8: {class_v8} ({conf_v8:.2f}) | YOLOv10: {class_v10} ({conf_v10:.2f})")
if class_v8 and class_v10:
if class_v8 != class_v10 and abs(conf_v8 - conf_v10) >= 0.4:
print("\n[+] Found adversarial image!")
print(f" YOLOv8 → {class_v8} ({conf_v8:.2f})")
print(f" YOLOv10 → {class_v10} ({conf_v10:.2f})")
submit_image(img_path)
break
Results
After running the exploit, we successfully found an adversarial image:
1
2
3
4
5
[16] YOLOv8: Speed Limit 90 (0.86) | YOLOv10: Speed Limit 60 (0.34)
[+] Found adversarial image!
YOLOv8 → Speed Limit 90 (0.86)
YOLOv10 → Speed Limit 60 (0.34)
The server responded with the flag:
1
<h2>🎉 FLAG: NHNC{you_kn0w_h0w_t0_d0_adv3rs3ria1_attack}</h2>
Why This Worked
YOLO models are CNN-based and sensitive to small perturbations, especially in earlier convolution layers. YOLOv8 and YOLOv10 likely have slightly different weights, training data, or hyperparameters, meaning they respond differently to noise.
The transformation pipeline ensured we created images in the decision boundary space — areas where small input changes cause big output changes. This is a textbook black-box adversarial attack. We didn’t need gradients, only output labels and confidence scores.
This challenge highlights critical security considerations for production ML systems:
- Model robustness testing before deployment
- Version-aware validation when updating models
- Adversarial training to improve resilience
- Ensemble methods to reduce single-point failures
The attack demonstrates how even natural-looking image transformations can exploit subtle differences between model versions, making this a realistic threat vector in real-world applications.